Stories



-
![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]()
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
RT STORIES
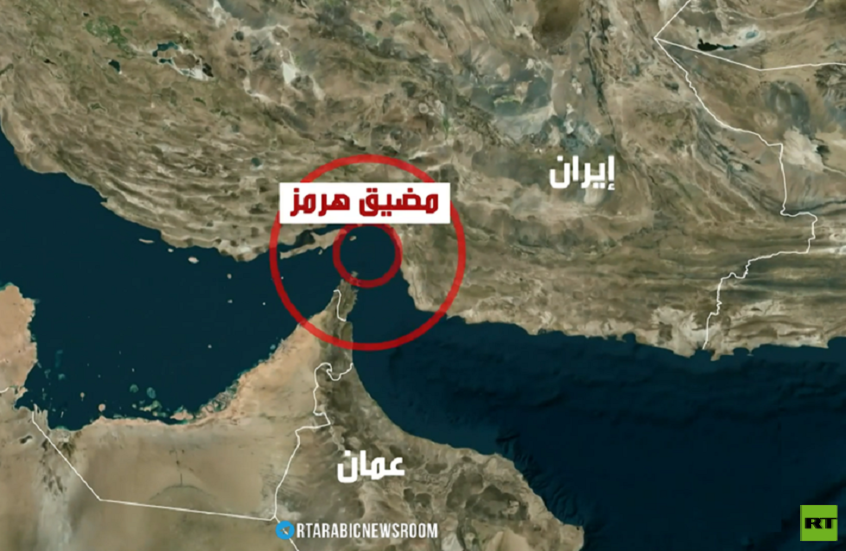
الجيش الإيراني: سيطرتنا على هرمز قد تؤدي تدريجيا لإخراج واشنطن من المنطقة
![الجيش الإيراني: سيطرتنا على هرمز قد تؤدي تدريجيا لإخراج واشنطن من المنطقة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
البحرين تدين "تجدد الاعتداء الإيراني" على أراضيها وتدعو لتحرك دولي لوقفه
![البحرين تدين "تجدد الاعتداء الإيراني" على أراضيها وتدعو لتحرك دولي لوقفه]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
البحرين تطلق صفارات الإنذار للمرة الثانية تحسبا لهجوم إيراني
![البحرين تطلق صفارات الإنذار للمرة الثانية تحسبا لهجوم إيراني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"الوضع لا يزال غير واضح".. مسؤول أمريكي يؤكد استهداف إيران لمنشآت أمريكية في البحرين والكويت
!["الوضع لا يزال غير واضح".. مسؤول أمريكي يؤكد استهداف إيران لمنشآت أمريكية في البحرين والكويت]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الأمريكي يعلن شن ضربات على 10 مواقع بمضيق هرمز
![الجيش الأمريكي يعلن شن ضربات على 10 مواقع بمضيق هرمز]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فانس مدافعا عن استراتيجية واشنطن تجاه إيران: أمريكا رابحة في الحالتين (فيديو)
![فانس مدافعا عن استراتيجية واشنطن تجاه إيران: أمريكا رابحة في الحالتين (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وسط حراك دبلوماسي متسارع.. مصر وإيران تبحثان فرص التوصل إلى اتفاق نهائي
![وسط حراك دبلوماسي متسارع.. مصر وإيران تبحثان فرص التوصل إلى اتفاق نهائي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]() اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
-
![مونديال 2026]()
مونديال 2026
RT STORIES
قمم مرتقبة.. مواعيد مباريات دور الـ32 في كأس العالم 2026
![قمم مرتقبة.. مواعيد مباريات دور الـ32 في كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ميسي يحطم رقما قياسيا جديدا في كأس العالم 2026
![ميسي يحطم رقما قياسيا جديدا في كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نهاية دور المجموعات.. تعرف على جميع المتأهلين في مونديال 2026
![نهاية دور المجموعات.. تعرف على جميع المتأهلين في مونديال 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مونديال 2026.. الجزائر تتأهل إلى الدور الثاني بعد تعادل درامي أمام النمسا
![مونديال 2026.. الجزائر تتأهل إلى الدور الثاني بعد تعادل درامي أمام النمسا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مودريتش يتفوق على مارادونا ويكتب رقما تاريخيا في المونديال
![مودريتش يتفوق على مارادونا ويكتب رقما تاريخيا في المونديال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
إنجاز مونديالي.. الكونغو الديمقراطية تكتب التاريخ في المجموعة الـ11
![إنجاز مونديالي.. الكونغو الديمقراطية تكتب التاريخ في المجموعة الـ11]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
كولومبيا تحافظ على القمة.. والبرتغال تعبر إلى دور الـ32 من مركز الوصافة
![كولومبيا تحافظ على القمة.. والبرتغال تعبر إلى دور الـ32 من مركز الوصافة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نبض اليوم الـ18.. كأس العالم 2026 يبدأ وجهه الحقيقي وانطلاق الأدوار الإقصائية
![نبض اليوم الـ18.. كأس العالم 2026 يبدأ وجهه الحقيقي وانطلاق الأدوار الإقصائية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![مونديال 2026]() مونديال 2026
مونديال 2026
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
الدفاع الروسية: إسقاط 213 مسيرة أوكرانية غربي البلاد
![الدفاع الروسية: إسقاط 213 مسيرة أوكرانية غربي البلاد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قتيل ومصاب وحريق بمصفاة للنفط بهجوم مسيرات أوكرانية جنوب روسيا
![قتيل ومصاب وحريق بمصفاة للنفط بهجوم مسيرات أوكرانية جنوب روسيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أوكرانيا تأمل في الحصول على 154 مليار دولار إضافية من حلفائها الغربيين قبل 2030
![أوكرانيا تأمل في الحصول على 154 مليار دولار إضافية من حلفائها الغربيين قبل 2030]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الروسي يستهدف بمسيرات جوية مصفاة نفط قرب زابوروجيه
![الجيش الروسي يستهدف بمسيرات جوية مصفاة نفط قرب زابوروجيه]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"جزار يراهن على القتلى".. القائد العام لقوات كييف يدفع بجنوده إلى المجهول لإنقاذ استراتيجيته
!["جزار يراهن على القتلى".. القائد العام لقوات كييف يدفع بجنوده إلى المجهول لإنقاذ استراتيجيته]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فيتسو: سلوفاكيا لن تدعم خلال قمة الناتو تمويل الصراع في أوكرانيا
![فيتسو: سلوفاكيا لن تدعم خلال قمة الناتو تمويل الصراع في أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
صحيفة: زيلينسكي يستخدم تكتيكات الرايخ الثالث ضد بيلاروس
![صحيفة: زيلينسكي يستخدم تكتيكات الرايخ الثالث ضد بيلاروس]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![إسرائيل ولبنان يتوصلان إلى اتفاق إطار]()
إسرائيل ولبنان يتوصلان إلى اتفاق إطار
RT STORIES
الجيش الإسرائيلي يعلن تصفية عنصرين بـ"حزب الله" في جنوب لبنان (فيديو)
![الجيش الإسرائيلي يعلن تصفية عنصرين بـ"حزب الله" في جنوب لبنان (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعد "الاتفاق الإطاري" مع لبنان.. نتنياهو يعرض المناطق التي ستبدأ فيها المرحلة التجريبية (صورة)
![بعد "الاتفاق الإطاري" مع لبنان.. نتنياهو يعرض المناطق التي ستبدأ فيها المرحلة التجريبية (صورة)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
"هآرتس": بنود "الاتفاق الإطار" الموقع في واشنطن تمهد الطريق لتحويل جنوب لبنان إلى "غزة 2"
!["هآرتس": بنود "الاتفاق الإطار" الموقع في واشنطن تمهد الطريق لتحويل جنوب لبنان إلى "غزة 2"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وليد جنبلاط يرصد "أمرا غريبا" في الاتفاق بين لبنان وإسرائيل: "المربع الأسود"
![وليد جنبلاط يرصد "أمرا غريبا" في الاتفاق بين لبنان وإسرائيل: "المربع الأسود"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
هيئة علماء بيروت تحذر السلطات اللبنانية من خيار قاتل بعد توقيعها اتفاق الإطار مع إسرائيل
![هيئة علماء بيروت تحذر السلطات اللبنانية من خيار قاتل بعد توقيعها اتفاق الإطار مع إسرائيل]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قاسم: "اتفاق الإطار" بين بيروت وإسرائيل مذلة وعار
![قاسم: "اتفاق الإطار" بين بيروت وإسرائيل مذلة وعار]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لبنان.. إجراءات أمنية مشددة وعاجلة لمنع الشغب والإخلال بالأمن
![لبنان.. إجراءات أمنية مشددة وعاجلة لمنع الشغب والإخلال بالأمن]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![إسرائيل ولبنان يتوصلان إلى اتفاق إطار]() إسرائيل ولبنان يتوصلان إلى اتفاق إطار
إسرائيل ولبنان يتوصلان إلى اتفاق إطار
-
![زلزال فنزويلا]()
زلزال فنزويلا
RT STORIES
ارتفاع حصيلة ضحايا زلزال فنزويلا إلى 1430 قتيلا
![ارتفاع حصيلة ضحايا زلزال فنزويلا إلى 1430 قتيلا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سوريا ترسل فريق إنقاذ إلى فنزويلا للمشاركة في جهود إزالة آثار الزلزال
![سوريا ترسل فريق إنقاذ إلى فنزويلا للمشاركة في جهود إزالة آثار الزلزال]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![زلزال فنزويلا]() زلزال فنزويلا
زلزال فنزويلا
-
![فيديوهات]()
فيديوهات
RT STORIES
روسيا.. طفل صيني يتألق في نهائيات بطولة رقص الصالات
![روسيا.. طفل صيني يتألق في نهائيات بطولة رقص الصالات]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
فنزويلا.. مشاهد مروعة لانهيار الأبراج السكنية
![فنزويلا.. مشاهد مروعة لانهيار الأبراج السكنية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات



































مشكلة "الثقة المفرطة" في الذكاء الاصطناعي تقترب من الحل
قد يكون الذكاء الاصطناعي، بما يملكه من مخزون هائل من المعرفة، مفيدا للغاية، إلا أن له عيبا واحدا قد يحدّ من مزاياه، وهو الثقة المفرطة في الإجابة.

فأي إجابة يقدمها، سواء كانت مبنية على استدلال مدروس أو مجرد تخمين، يطرحها بالقدر نفسه من الثقة.
واكتشف باحثون في مختبر علوم الحاسوب والذكاء الاصطناعي بمعهد ماساتشوستس للتكنولوجيا أن أصل هذه الثقة المفرطة يعود إلى خلل محدد في طريقة تدريب النماذج، وقد طوروا أسلوبا جديدا يهدف إلى معالجة هذا الخلل دون التأثير على دقة الأداء.
وتُعرف هذه الطريقة باسم RLCR (التعلم المعزز باستخدام مكافآت المعايرة)، وقد وُصفت في بحث منشور على منصة arXiv، ومن المقرر تقديمه في المؤتمر الدولي للتعلم الآلي ICLR 2026 في ريو دي جانيرو. وتعتمد هذه المنهجية على تدريب النماذج اللغوية على تقديم إجابات مرفقة بتقدير لدرجة الثقة، أي أن النموذج لا يكتفي بالإجابة، بل يعبّر أيضا عن مستوى عدم يقينه.

ميتا تطلق أداة جديدة تتيح للآباء مراقبة محادثات أطفالهم مع الذكاء الاصطناعي
ما المشكلة؟
تقوم أساليب التعلم المعزز المستخدمة في أحدث نماذج التفكير الاصطناعي على مكافأة الإجابة الصحيحة ومعاقبة الإجابة الخاطئة، دون التمييز بين طريقة الوصول إلى النتيجة. وبالتالي، يحصل النموذج الذي يصل إلى الإجابة الصحيحة عبر استنتاج منطقي، على نفس المكافأة التي يحصل عليها نموذج آخر وصل إليها عن طريق التخمين.
ومع مرور الوقت، يؤدي ذلك إلى ترسيخ سلوك لدى النماذج يجعلها تميل إلى تقديم إجابات واثقة حتى في الحالات التي تفتقر فيها إلى الأدلة الكافية.
وتترتب على هذه الثقة المفرطة آثار سلبية، خاصة عند استخدام هذه النماذج في مجالات حساسة مثل الطب أو القانون أو التمويل، حيث تعتمد القرارات البشرية على مخرجات الذكاء الاصطناعي. فالنموذج الذي يعبر عن ثقة عالية غير دقيقة قد يكون أكثر خطورة من نموذج يخطئ بوضوح، لأن المستخدم قد لا يدرك ضرورة التحقق من الإجابة.
ويشرح طالب الدراسات العليا في معهد ماساتشوستس للتكنولوجيا وأحد مؤلفي الدراسة، ميهول داماني، قائلا:
"إن أساليب التدريب التقليدية بسيطة وفعالة، لكنها لا تشجع النموذج على التعبير عن عدم اليقين أو قول (لا أعرف)، لذلك يتعلم النموذج بطبيعته أن يخمّن عندما لا يكون واثقا".
ما الحل؟
تعالج طريقة RLCR هذه المشكلة بإضافة عنصر واحد إلى دالة المكافأة، وهو مقياس "براير" (Brier score)، المستخدم لقياس مدى تطابق ثقة النموذج مع دقته الفعلية. خلال التدريب، تتعلم النماذج تقييم كل من الإجابة وعدم يقينها في الوقت نفسه، بحيث تقدم الجواب مع تقدير لمستوى الثقة.
وبذلك تتم معاقبة كل من الإجابات الخاطئة ذات الثقة المبالغ فيها، والإجابات الصحيحة المصحوبة بعدم ثقة غير مبررة، مما يساعد على تحقيق توازن أفضل بين الدقة والتعبير الواقعي عن الثقة.
المصدر: Naukatv.ru
إقرأ المزيد

OpenAI تحل لغز الهوس الغريب لتطبيق ChatGPT بالمخلوق اﻷسطوري "غولبن"
تمكنت شركة OpenAI من حل لغز تسبب في تحول روبوت الدردشة الشهير ChatGPT إلى كائن مهووس بالمخلوقات الأسطورية، وخصوصا "الغولبن" (goblins).

لا أثق به ثقة عمياء.. مدفيديف يتحدث عن التحدي الأكبر في مواجهة الذكاء الاصطناعي
كشف نائب رئيس مجلس الأمن الروسي دميتري مدفيديف أنه يستخدم برمجيات الذكاء الاصطناعي في عمله اليومي، لكنه لا يثق بها ثقة عمياء.

DeepSeek تطلق ذكاء اصطناعيا جديدا يتفوق على معظم النماذج مفتوحة المصدر
أطلقت DeepSeek الصينية أحدث نماذجها في مجال الذكاء الاصطناعي، الإصدار الرابع (V4)، في خطوة جديدة تعكس تصاعد المنافسة العالمية في هذا القطاع.

عطل أم تصرف عدواني؟.. روبوت يفلت من السيطرة في مهرجان صيني (فيديو)
أثارت حادثة غريبة خلال مهرجان في الصين جدلا كبيرا حول سلامة الروبوتات المتقدمة، بعد أن ظهر روبوت شبيه بالإنسان وهو يتحرك بشكل غير متوقع، ما أثار صدمة الحاضرين.

DeepSeek تحذر المستخدمين من انتشار معلومات كاذبة عنها
حذّرت شركة DeepSeek الصينية مستخدمي الإنترنت من انتشار معلومات كاذبة عنها، وأوصت باستخدام مواقعها الرسمية.





























































































التعليقات